K8s Concept and Kubernetes Architecture Tutorials for Beginner
A Kubernetes tutorials with detailed explanations
A Kubernetes cluster is a set of physical or virtual machines and other infrastructure resources that are needed to run your containerized app’s. Each machine in a Kubernetes cluster is called a node. There are two types of node in each Kubernetes cluster:
Master node(s): hosts the Kubernetes control plane components and manages the cluster
Worker node(s): runs your containerized applications

Kubernetes Master Node Components:
Master is responsible for managing the complete cluster.
Master node can be access via the CLI, GUI, or API. It has four components: ETCD, Scheduler, Controller and API Server.
The Kubernetes API server provides the interface for users and administrators to interact with the cluster. It accepts and processes REST API requests and communicates with other Kubernetes components to manage the cluster.
The etcd store is used for storing configuration data and cluster state information. It provides a distributed and reliable key-value store that is used by the Kubernetes API server and other components to maintain the cluster’s state.
The Kubernetes controller manager is responsible for running various controllers that monitor the state of the cluster and take action to ensure that the desired state is maintained. For example, it can start or stop pods, replicate controllers, and manage endpoints.
Finally, the Kubernetes scheduler is responsible for determining which worker node a newly created pod should be scheduled on. It takes into account various factors such as resource availability, workload constraints, and node affinity.

API server manager
- Masters communicate with the rest of the cluster through the kube-apiserver, the main access point to the control plane.
- It validates and executes user’s REST commands
- kube-apiserver also makes sure that configurations in etcd match with configurations of containers deployed in the cluster.
Controller manager —
The controllers are the brain behind orchestration.
• They are responsible for noticing and responding when nodes, containers or endpoints goes down. The controllers makes decisions to bring up new containers in such cases.
• The kube-controller-manager runs control loops that manage the state of the cluster by checking if the required deployments, replicas, and nodes are running in the cluster.
Scheduler -
- It looks for newly created containers and assigns them to Nodes.
- The scheduler is responsible for distributing work or containers across multiple nodes.
ETCD —
- ETCD is a distributed reliable key-value store used by Kubernetes to store all data used to manage the cluster.
- When you have multiple nodes and multiple masters in your cluster, etcd stores all that information on all the nodes in the cluster in a distributed manner.
- ETCD is responsible for implementing locks within the cluster to ensure there are no conflicts between the Masters
Kubernetes Worker Node Components —
Kubelet -
- Worker nodes have the kubelet agent that is responsible for interacting with the master to provide health information of the worker node
- To carry out actions requested by the master on the worker nodes.
Kube proxy —
- The kube-proxy is responsible for ensuring network traffic is routed properly to internal and external services as required and is based on the rules defined by network policies in kube-controller-manager and other custom controllers.
Kubernetes POD’s —
- Basic scheduling unit in Kubernetes. Pods are often ephemeral
• Kubernetes doesn’t run containers directly; instead it wraps one or more containers into a higher-level structure called a pod.
• It is also the smallest deployable unit that can be created, schedule, and managed on a Kubernetes cluster. Each pod is assigned a unique IP address within the cluster.
• Pods can hold multiple containers as well, but you should limit yourself when possible. Because pods are scaled up and down as a unit, all containers in a pod must scale together, regardless of their individual needs. This leads to wasted resources


Scaling Pods -
· All containers within the pod get scaled together.
· You cannot scale individual containers within the pods. The pod is the unit of scale in K8s.
· Recommended way is to have only one container per pod. Multi container pods are very rare.
Imperative vs Declarative commands —
- Kubernetes API defines a lot of objects/resources, such as namespaces, pods, deployments, services, secrets, config maps etc.
- There are two basic ways to deploy objects in Kubernetes: Imperatively and Declaratively Imperatively
Imperatively
- Involves using any of the verb-based commands like kubectl run, kubectl create, kubectl expose, kubectl delete, kubectl scale and kubectl edit
- Suitable for testing and interactive experimentation
Declaratively
- Objects are written in YAML files and deployed using kubectl create or kubectl apply
- Best suited for production environments
Kubernetes Manifest /Spec file —
- K8s object configuration files — Written in YAML or JSON
- They describe the desired state of your application in terms of Kubernetes API objects. A file can include one or more API object descriptions (manifests).
# manifest file template
apiVersion — version of the Kubernetes API used to create the object
kind — kind of object being created
metadata — Data that helps uniquely identify the object, including a name and optional namespace
spec — configuration that defines the desired for the object
Replication Controller
- A single pod may not be sufficient to handle the user traffic. Also if this only pod goes down because of a failure, K8s will not bring this pod up again automatically
- Replication Controller ensures high availability by replacing the unhealthy/dead pods with a new one to ensure required replicas are always running inside a cluster
- In order to prevent this, we would like to have more than one instance or POD running at the same time inside the cluster
- Another reason we need replication controller is to create multiple PODs to share the load across them.
- Replica controller is deprecated and replaced by Replicaset
ReplicaSet
• ReplicaSets are a higher-level API that gives the ability to easily run multiple instances of a given pod
• ReplicaSets ensures that the exact number of pods(replicas) are always running in the cluster by replacing any failed pods with new ones
• The replica count is controlled by the replicas field in the resource definition file
• Replicaset uses set-based selectors whereas replicacontroller uses equality based selectors
Labels and Selectors —
- Selectors allows to filter the objects based on labels
- The API currently supports two types of selectors: equality-based and set-based
- A label selector can be made of multiple requirements which are comma-separated
Namespaces -
By default, a Kubernetes cluster is created with the following three namespaces:
- default: It’s a default namespace for users. By default, all the resource created in Kubernetes cluster are created in the default namespace
- Kube-system: It is the Namespace for objects created by Kubernetes systems/control plane. Any changes to objects in this namespace would cause irreparable damage to the cluster itself
- kube-public: Namespace for resources that are publicly readable by all users. This namespace is generally reserved for cluster usage like Configmaps and Secrets
Services — 3 types (ClusterIP, NodePort and LoadBalance)
- Services logically connect pods across the cluster to enable networking between them
- Services makes sure that even after a pod(back-end) dies because of a failure, the newly created pods will be reached by its dependency pods(front-end) via services
- Services point to pods directly using labels. Services do not point to deployments or ReplicaSets. So, all pods with the same label gets attached to same service
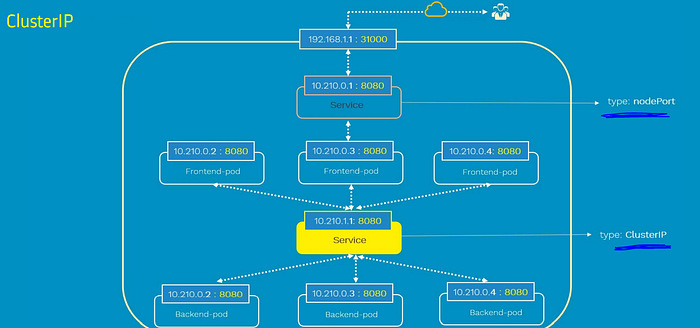
ClusterIP -
ClusterIP service is the default Kubernetes service.
- It gives you a service inside your cluster that other apps inside
your cluster can access - It restricts access to the application within the cluster itself
and no external access - Useful when a front-end app wants to communicate with
back-end
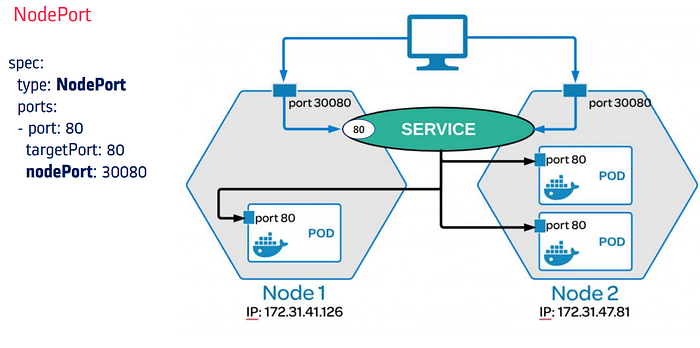
NodePort -
- NodePort opens a specific port on all the Nodes in the cluster and forwards any traffic that is received on this port to internal service.
- Useful when front end pods are to be exposed outside the cluster for users to access it.
- NodePort is build on top of ClusterIP service by exposing the ClusterIP service outside of the cluster .
- NodePort must be within the port range 30000-32767.If you don’t specify this port, a random port will be assigned. It is recommended to let k8s auto assign this port
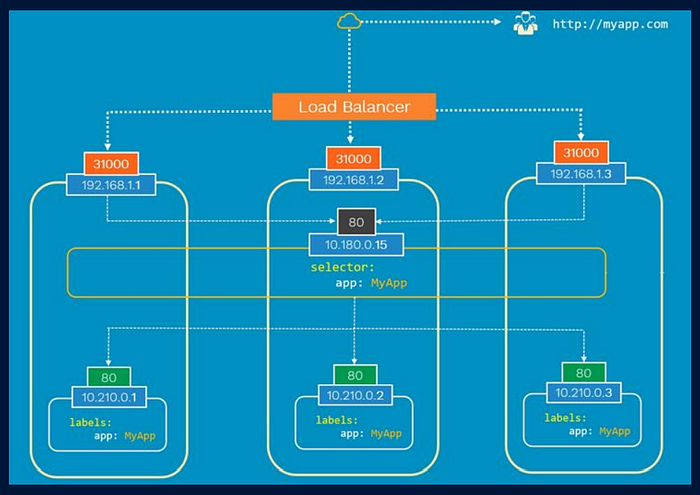
LoadBalance -
A LoadBalancer service is the standard way to expose a Kubernetes service to the internet.
- A LoadBalancer service is the standard way to expose a Kubernetes service to the internet
- All traffic on the port you specify will be forwarded to the service.
- There is no filtering, no routing, etc. This means you can send almost any kind of traffic to it, like HTTP, TCP, UDP or WebSocket’s.
- Few limitations with LoadBalancer:
▪ Every service exposed will gets it’s own IP address
▪ It gets very expensive to have external IP for each of the
service(application)
Ingress Resource(rules) —
- With cloud LoadBalancers, we need to pay for each of the service that is exposed using LoadBalancer as the service type. As services grow in number, complexity to manage SSLs, Scaling, Auth etc., also increase
- Ingress allows us to manage all of the above within the Kubernetes cluster with a definition file, that lives along with the rest of your application deployment files.
- Ingress controller can perform load balancing, Auth, SSL and URL/Path based routing configurations by being inside the cluster living as a Deployment or a DaemonSet.
- Ingress helps users access the application using a single externally accessible URL, that you can configure to route to different services within your cluster based on the URL path, at the same time terminate SSL/TLS
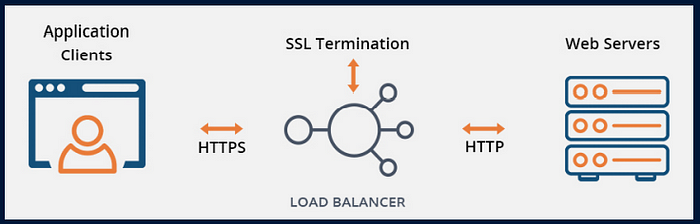
Why SSL Termination at LoadBalancer?
- SSL termination/offloading represents the end or termination point of an SSL connection
- SSL termination at LoadBalancer decrypts and verifies data on the load balancer instead of the application server. Unencrypted traffic is sent between the load balancer and the backend servers
- It is desired because decryption is resource and CPU intensive
- Putting the decryption burden on the load balancer enables the server to spend processing power on application tasks, which helps improve performance
Ingress Controller
- Ingress resources cannot do anything on their own. We need to have an Ingress controller in order for the Ingress resources to work
- Ingress controller implements rules defined by ingress resources.
- Ingress controllers are to be exposed outside the cluster using NodePort or with a Cloud Native LoadBalancer.
- Ingress controller can perform load balancing, Auth, SSL and URL/Path based routing configurations by being inside the cluster living as a Deployment or a DaemonSet
Nginx Ingress Controller -
- Ingress-nginx is an Ingress controller for Kubernetes using NGINX as a reverse proxy and load balancer
- Routes requests to services based on the request host or path, centralizing a number of services into a single entrypoint. Ex: www.mysite.com or www.mysite.com/stats
Scheduling -
Taints and Tolerations
- Taints are applied to nodes(lock) Tolerations are applied to pods(keys)
- In short, pod should tolerate node’s taint in order to run in it. It’s like having a correct key with pod to unlock the node to enter it
- Taints and tolerations work together to ensure that pods are not scheduled onto inappropriate nodes
- By default, Master node is tainted. So you cannot deploy any pods on Master
- To check taints applied on any node use kubectl describe node node-name
1. NoSchedule: no pod will be able to schedule onto node unless it has a matching toleration.
2. PreferNoSchedule: soft version of NoSchedule. The system will try to avoid placing a pod that does not tolerate the taint on the node, but it is not required
3. NoExecute: node controller will immediately evict all Pods without the matching toleration from the node, and new pods will not be scheduled onto the node
Example : kubectl taint nodes k8s-slave01 env=stag:NoSchedule
In the above case, node k8s-slave01 is tained with label env=stag and taint effect as NoSchedule. Only pods that matches this taint will be scheduled onto this node
nodeAffinity -
- Node affinity is specified as field nodeAffinity in PodSpec
- Node affinity is conceptually similar to nodeSelector — it allows you to manually schedule pods based on labels on the node. But it has few key enhancements:
There are currently two types of node affinity rules:
- requiredDuringSchedulingIgnoredDuringExecution: Hard requirement like nodeSelector. No matching node label, no pod scheduling!
- preferredDuringSchedulingIgnoredDuringExecution: Soft requirement. No matching node label, pod gets scheduled on other nodes!
- The IgnoredDuringExecution part indicates that if labels on a node change at runtime such that the affinity rules on a pod are no longer met, the pod will still continue to run on the node.
References — https://kubernetes.io/docs/concepts/ and Udemy and Youtube video’s
At this point we reached the end of our tutorial. I hope you enjoyed reading this article, feel free to add your comments, thoughts or feedback and don’t forget to get in touch on Linkedin — @manoj-kumar